
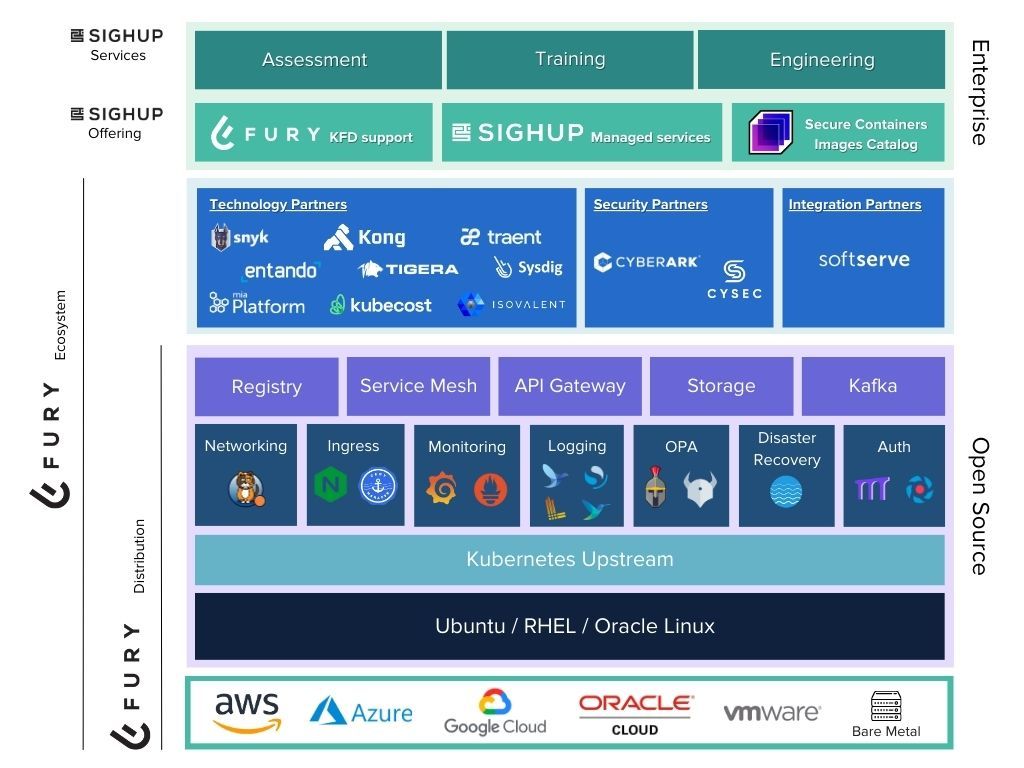
Kubernetes Fury Storage
The new Add-on Module which enables storage provisioning capabilities for Kubernetes Fury Distribution


In our previous blog post, we started diving deeper into how our latest release of Kubernetes Fury Distribution (KFD), v1.24, has expanded our distribution ecosystem. More specifically, we announced our new Core Module, Kubernetes Fury Auth, and presented why we implemented it into KFD.
In this article, we will explore the common challenges related to storage provisioning in Kubernetes and how our new Add-on Module, Kubernetes Fury Storage, addresses these issues.
How does data storage on Kubernetes works?
In Kubernetes, data stored within containers is considered ephemeral, meaning it only exists as long as the container is up and running. This can present a challenge for applications requiring persistent storage to operate properly.
To address this, Kubernetes offers, for example with cloud providers, a range of integrations that allows for dynamic storage provisioning, enabling storage resources to be automatically allocated and managed as the needs of the application change.
The challenges with Private Cloud / Hybrid / On-Premises clusters
However, when it comes to private clouds, hybrid, or on-premises clusters (a range of options representing a common stage of enterprises’ cloud native journey), the situation becomes a bit more complex. These environments may not have the same automatic access to features, such as dynamic provisioning, availability, or backup, that a cloud provider would offer. This can require additional involvement from Operations teams and add to the overall complexity of managing storage resources.
Common solutions
To solve these issues, several Kubernetes implementations are available that aim to make it easier to provision and manage storage in these types of environments. However, these solutions may not be complete, fully supported, or fully capable, making it difficult to rely on them in a production-grade environment.

Overview of Kubernetes Fury Storage
Kubernetes Fury Storage addresses the need for private cloud, hybrid, and on-premises environments by providing a way to provision and manage storage as easily as it would with a cloud provider.
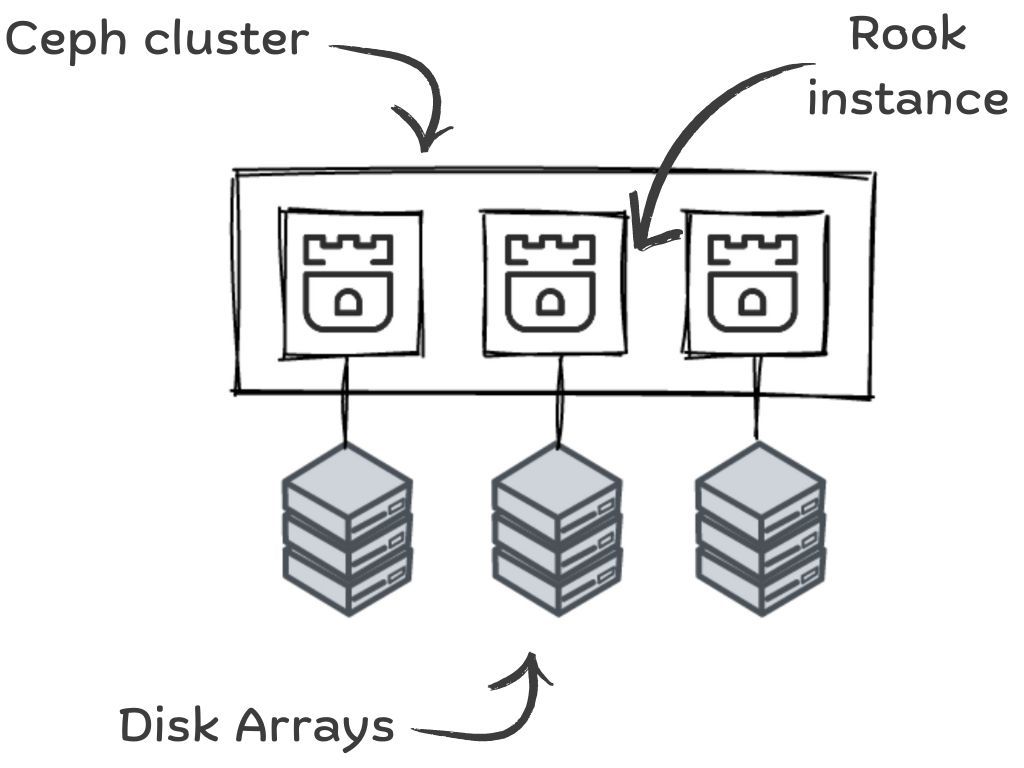
This Add-on Module comprises two components: Ceph and Rook.
Ceph
It is an Open Source distributed storage system that provides object, block, and file storage capabilities. Ceph is a standalone software that can be integrated with Kubernetes to supply persistent storage for containerized applications and provides a highly-available and scalable storage solution by automatically replicating data across multiple nodes in the cluster.
Rook
It is an Open Source Kubernetes Operator that allows to easily deploy and manage Ceph Clusters. Rook takes care of the operational tasks of deploying and managing a Ceph cluster, such as scaling, upgrading, and monitoring. Rook Operator also provides a Kubernetes-native way of provisioning and consuming storage by creating Kubernetes Custom Resources and using Kubernetes features like automatic scaling and self-healing.
Conclusions
By leveraging these two components, Kubernetes Fury Storage makes it possible to easily provision and manage storage resources in on-premises, hybrid clusters, or private clouds without the need for additional involvement from Operations teams or the added complexity of using custom solutions. This allows you to focus on running your applications without worrying about the underlying storage infrastructure.
