
Tenaris Data Science - Customer Success Story
SIGHUP and Tenaris Data Science Lab worked together to scale infrastructure and enhance productivity with Kubernetes Fury Distribution (KFD). Learn Tenaris customer success journey and how they leveraged Kubernetes Fury to automate applications management and training ML models with JupyterHub.


Introduction
Tenaris is a global manufacturer and supplier of steel pipes and related services, primarily for the energy industry. They use data science and machine learning to increase safety, quality and efficiency in industrial processes and predict equipment failures based on historical data.
Challenge
Since 2018 Tenaris has leveraged containerized data science workloads using traditional infrastructural technologies. They still relied on time-consuming manual operations and manual release cycles for updates and deployments. In terms of data science operations, everyone used to develop applications locally on their workstations, without a standardized working environment. Other tasks, like data exploration and data preparation, were performed using a shared Jupyter server.
The main goal in looking into Kubernetes Upstream and finding a supported upstream distribution was to increase speed and reduce errors on all the operations processes and standardize the data science tools.
Solution
The decision to use SIGHUP Kubernetes Fury was mainly to automate and speed up all the manual processes.
This is why Tenaris and SIGHUP joined forces to deploy SIGHUP Kubernetes Fury in its first ever Kubernetes cluster.
SIGHUP Kubernetes Fury was the Kubernetes upstream distribution of choice and it allowed a paradigm shift where everything is native Kubernetes workload: Jupyter notebook as pods, models deployed automatically via CI/CD with centralized logging, monitoring, and autoscaling for in-depth observability and performance.
Implementation details
The Tenaris cluster implements an on-premise hybrid architecture, with a mix of virtual, physical and GPU-optimized hardware to efficiently run machine learning models.
Kubernetes Fury Distribution ships the following tools out-of-the-box:
- Centralized infrastructural and application logging via Fluentd, Elasticsearch, Kibana
- Centralized monitoring with automatic service discovery using Prometheus, Grafana, Alertmanager
- Backup and disaster recovery using Velero
- Networking and networking policies via Calico
- Battle-tested ingress and virtual intra-cluster load balancing with standard Nginx ingress controller
In addition to the standardized Kubernetes Fury core modules (See them in Github), we have been actively working with the Tenaris Data Science team on a production-grade deployment/roll-out of Jupyter Hub for Kubernetes.
Jupyter Hub for Kubernetes: Data science at scale
Jupyter Hub for Kubernetes leverages the on-demand nature of the Jupyter notebooks workflow. Users can launch different configurations for their notebooks, maintaining local state thanks to Kubernetes storage features and volumes management.
CPU and GPU workloads
Besides the stateful nature of Jupyter workloads and the automation abstractions provided by Kubernetes for the management of storage and state, we can also leverage Kubernetes for advanced workload scheduling and hardware utilization.
Machine learning models can be, for example, dynamically deployed and automatically switched across different kinds of specialized nodes: CPU intensive workloads vs. memory intensive models vs. nodes equipped with GPUs.
Kubernetes will automatically know if there are available nodes with GPU and starts the notebook on the assigned node.
TensorBoard
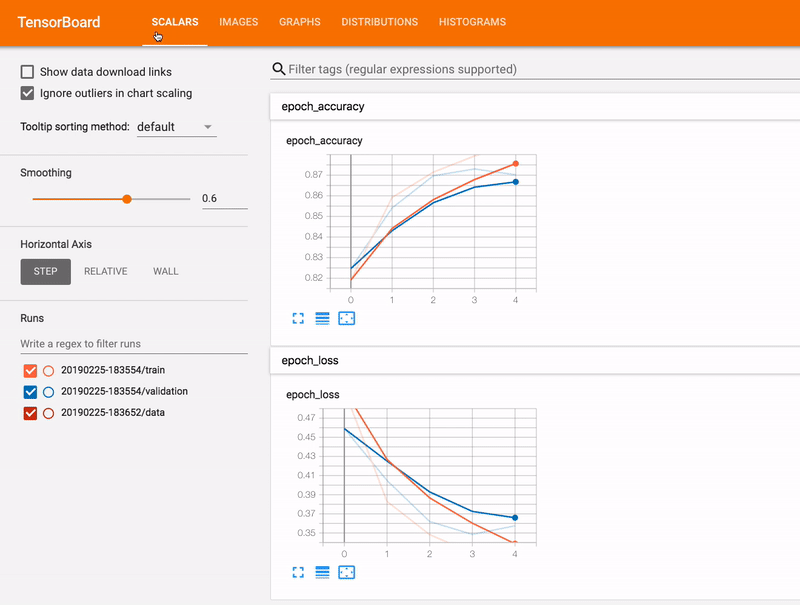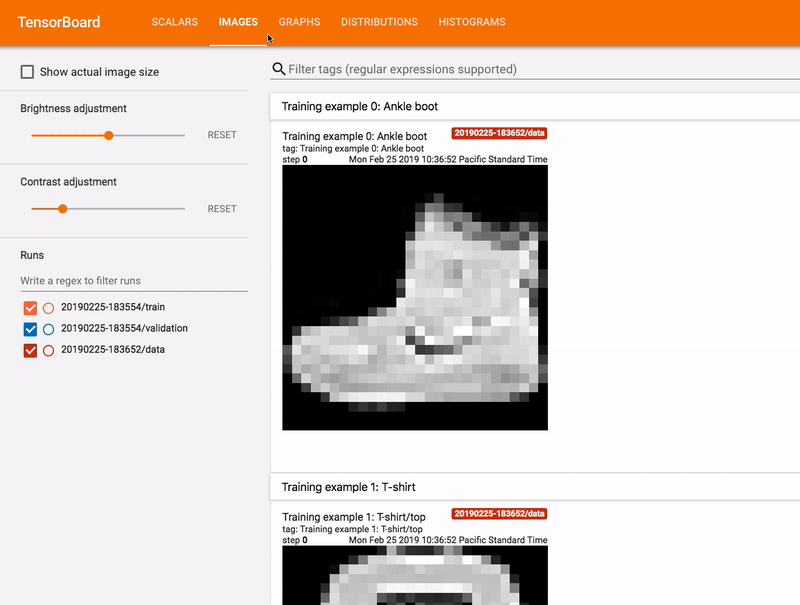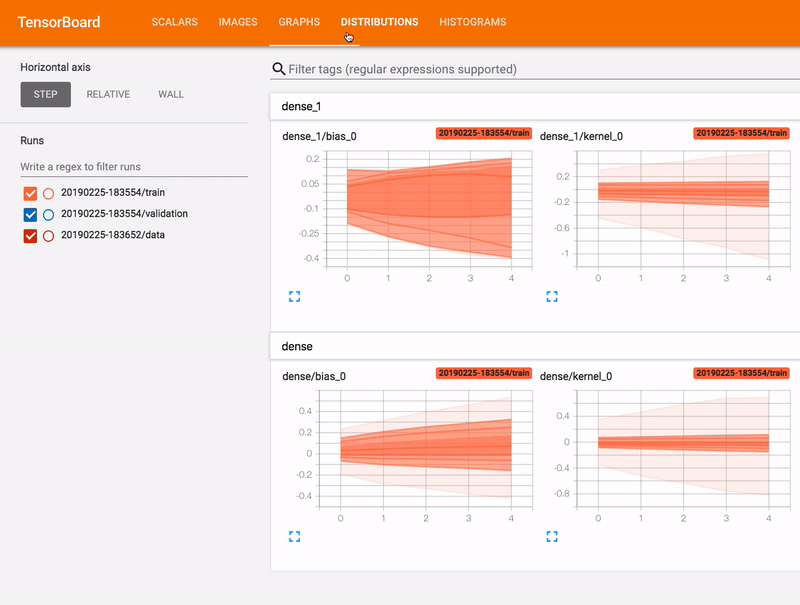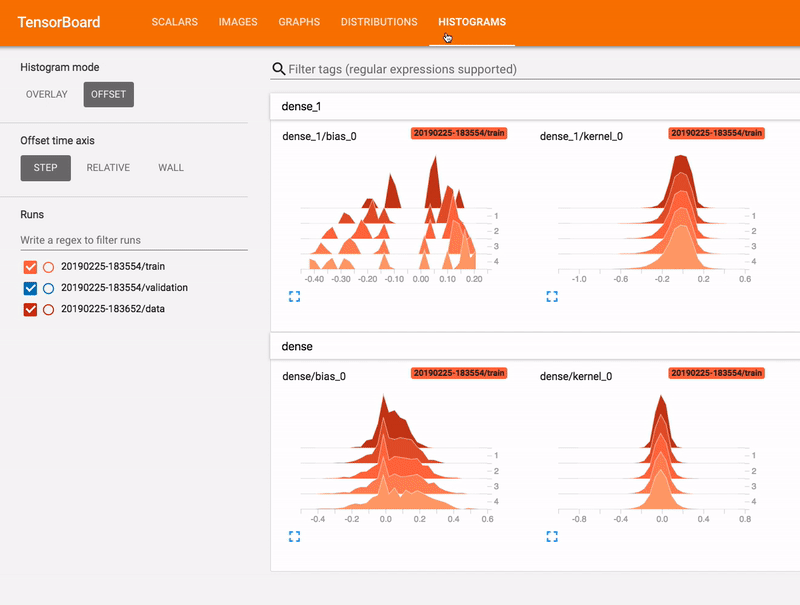
TensorFlow is the primary library used by the Tenaris Data Science team to train deep learning models, mainly for computer vision tasks. It offers a control board called TensorBoard for monitoring the training. To access it, it is necessary to expose a port on the Jupyter notebook. To achieve this, each user has a personal ingress configured on the cluster http proxy Nginx ingress controller. This ingress points to the on-demand user pod. This way, it is possible to work on some datasets and share TensorBoard with team members.
Machine learning model service
The adoption of Kubernetes also unlocks the CI/CD deployment of all the trained models. This way it is possible to speed up the delivery of all the user-facing projects.
We also leveraged auto-scaling capabilities to have an elastic infrastructure that scales on-demand as the number of requests increases.
When someone commits modifications to Git, all the containers are re-built and deployed on the staging environment in a matter of minutes. We choose tagging as a trigger for a production promotion.
Centralized monitoring and logging
Having a Kubernetes architecture with logging and monitoring installed via Fury Kubernetes Distribution unlocks centralized logging of all the workloads deployed in the cluster, automatic alerting when problems occur, and a preconfigured Grafana dashboard to see the cluster status.
Results
Kubernetes is proactively allowing the Tenaris Data Science team to improve software delivery processes, resources optimization, and an overall improved way of working through open source and standardization. Thanks to the capabilities of upstream Kubernetes and Fury KFD:
- Deployments of new models do not require manual intervention anymore;
- Notebooks are configured and shared in the team in a highly standardized and reproducible way;
- The team can now focus more time on applications themselves, rather than on cumbersome processes to put them in production.
Side notes
Professional services for migrating existing containerized applications
Even though the Tenaris Data Science team has high-level technological skills, which is not common in other similar teams, they needed support to transport their models expressed as docker-compose files in the CI/CD paradigm on Kubernetes.
SIGHUP has provided its expertise to deal with the activities.
Full-remote
Due to physical limitations, all the deployment and professional services have been performed remotely.
“We chose Fury distribution because it puts infrastructure as a code in the first place, it is open source, and integrates most of the infrastructure services we needed out-of-the-box. We were able to deploy both the Data Science Lab and the model service infrastructure 100% remotely.” -- Vincenzo Manzoni, Data Science Director, Tenaris.
“Working on premises installation requires a lot of flexibility to adapt to existing solutions and requirements. One of the most challenging requirements was to integrate virtual worker machines with physical GPU nodes used for deep learning. SIGHUP made it work at the first try! Working with their skilled professionals was a good learning experience” -- Andrea Rota, Senior Data Science Engineer, Tenaris.
